
EMI | Chercher ? Pas si simple…
 Mettons d'emblée fin à 2
mythes. L'on
ne trouve pas tout sur Internet et chercher n'est pas
si
facile…
Mettons d'emblée fin à 2
mythes. L'on
ne trouve pas tout sur Internet et chercher n'est pas
si
facile…
C'est pourquoi la bonne connaissance et la maîtrise des outils et des
techniques de
recherche est indispensable. Et cela commence aussi quelquefois en changeant
d'outils…
Quels sont-ils ? Que permettent-t-ils de trouver ? Quelques
réponses
ici…
SOMMAIRE
Voir aussi
 Etapes
Etapes Google
Google Qwant
Qwant Veiller
Veiller Outils des pros
Outils des pros

 DYS
DYS
 NO-DYS
NO-DYS
Pourquoi c'est difficile ?
On trouve tout sur Internet ?
Il suffit d'aller sur Google… et il y a toujours des réponses… Les bonnes ?
Google a réponse à tout ?
On trouve sur Google beaucoup d'informations de qualité variable, mais comment s'assurer d'avoir toutes les informations nécessaires pour un travail universitaire ?
Quoi et où ?
Infotrack
Infotrack est un site de formation aux compétences informationnelles de l’Université de Genève (Suisse).
 infotrack.unige.ch/
infotrack.unige.ch/
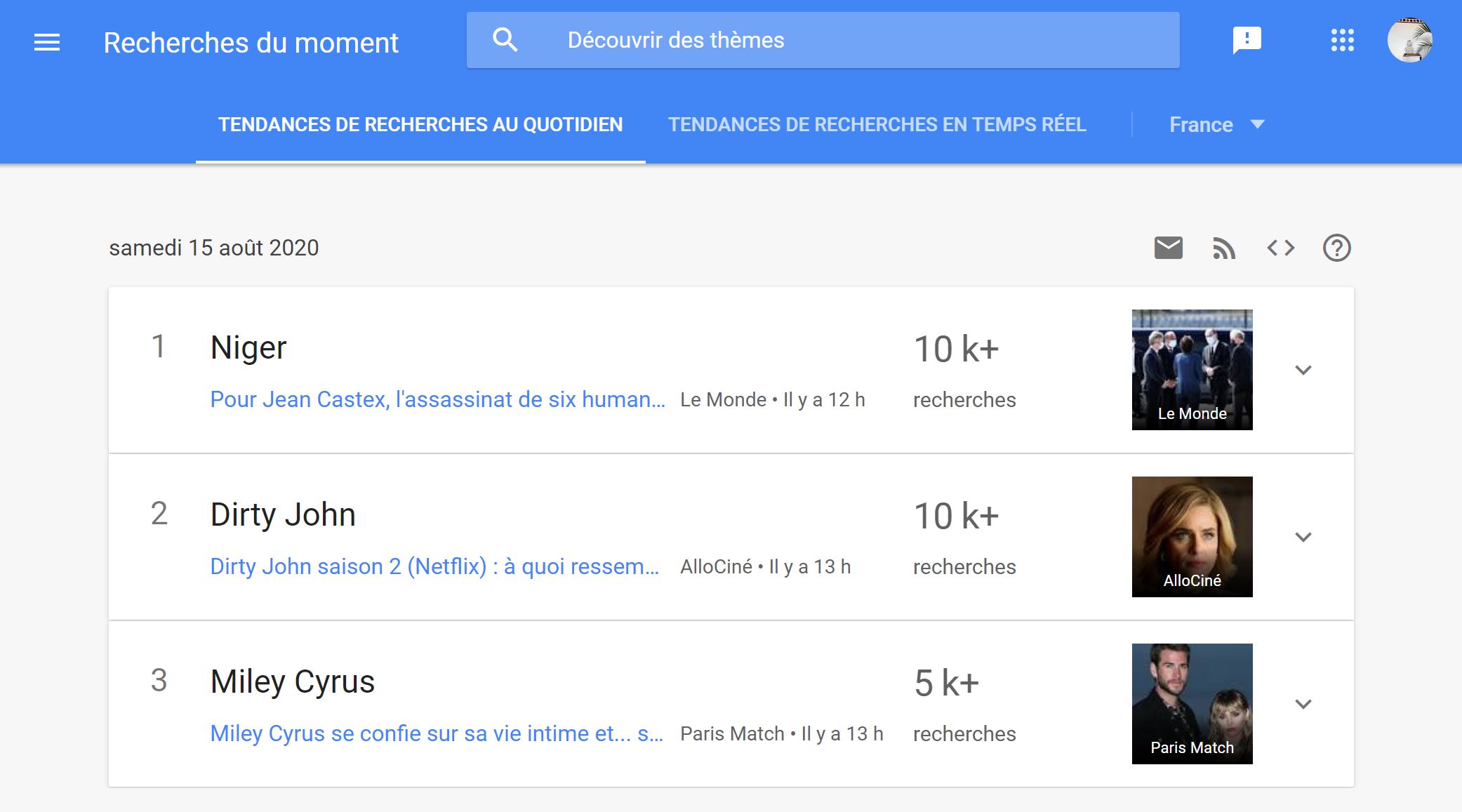
L'outil Google trend permet de se faire un idée de l'actualité de la recherche par pays, sujet, date.

Pour aller plus loin !
Retrouvez de nombreuses capsules vidéos sur la recherche réalisées par l'Université du Québec toujours très informatives et accessibles. A découvrir d'urgence si vous ne connaissez pas !
guides.bib.umontreal.ca/
Le site lumni.fr, qui n'est plus à présenter, propose une fiche méthodo simplifiée sur la recherche documentaire.
https://www.lumni.fr/article/faire-une-recherche-documentaire
Les langues du Web
Quelles sont les principales langues que vous allez trouver sur le Web ? Ce petit exercice va vous permettre de le découvrir !
Quels obstacles ?
Infobésité
Il y a trop d'informations !
Quelle que soit la recherche, vous trouvez généralement des milliers, quand ce ne sont pas des millions de réponses. Mais qui peut dire si les bonnes réponses se trouvent à la première, la dixième ou la cent vingt septième page ?
« Trop d'information tue l'information »
Hétérogénéité
Sites personnels, d'administration, d'entreprises, ici encore la diversité des formes et des types est quasi sans limites et il n'est pas si simple de trouver le type d'information recherchée.
De la même manière, l'on trouve des images, du texte, des vidéos, des sons, et tous ces types peuvent être informatifs…
Mais aussi homogénéité…
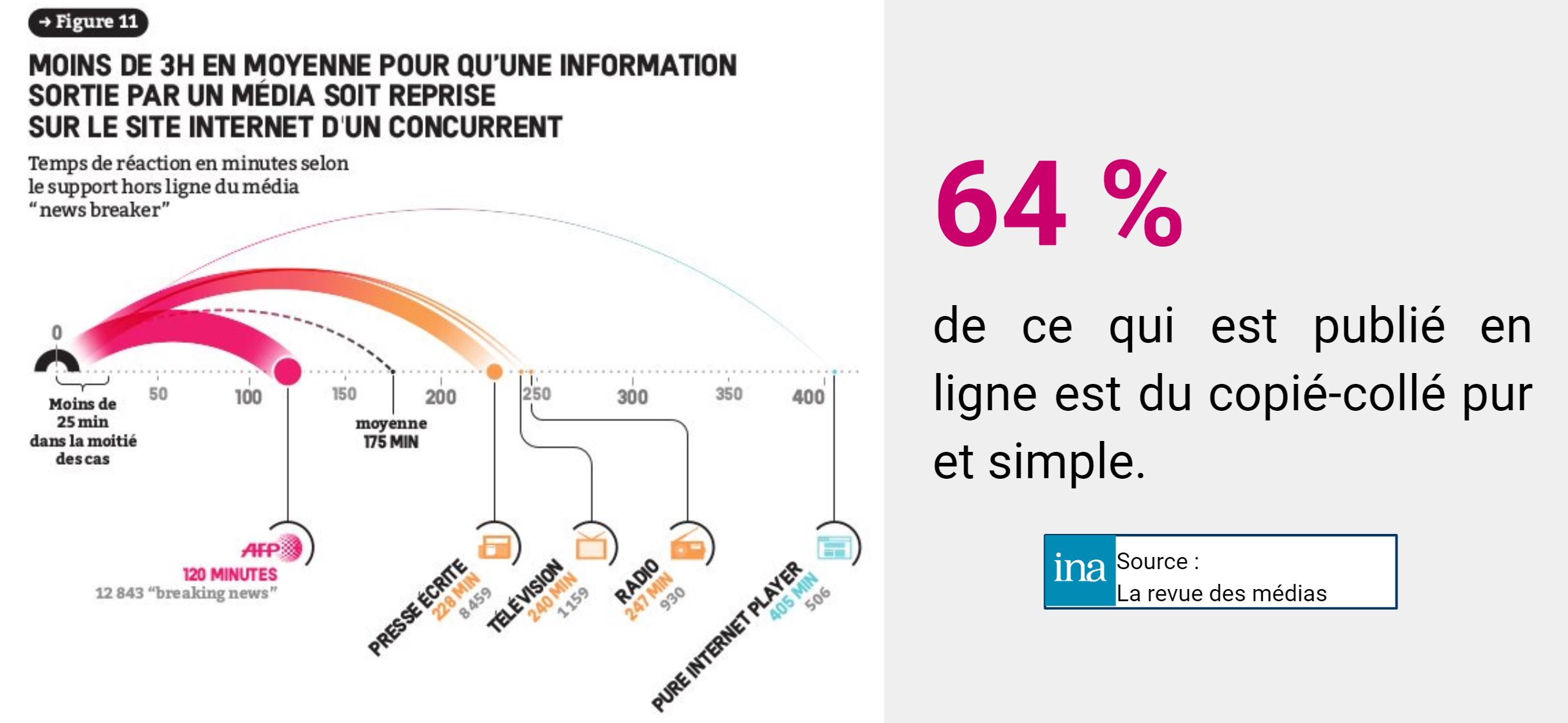
Les auteurs de « L’Information à tout prix » (Ina Éditions), interrogés par la revue des médias répondent à quelques questions. Le développement de l’information sur Internet conduit-il au règne du copié-collé au détriment de l’information de qualité ? Peut-on inventer de nouveaux modèles économiques pour les médias afin de tirer le meilleur parti des nouvelles technologies ?
Et la réponse est cruelle…
« Sur l’actualité chaude, sur ce qui fait événement, nous avons montré que 2/3 du contenu était en fait du copié-collé, ce qui vient, d’une part, d’une utilisation très forte des dépêches d’agences, que ce soit l’AFP mais aussi Reuters ou Associated Press. D’autre part, cela est lié au fait qu’on a malheureusement des rédactions qui ont pas mal réduit la voilure. Si vous avez moins de journalistes et que vous leur demandez, pour alimenter en continu un site Internet, de produire six, sept, huit articles par jour, ils vont de facto faire beaucoup de copies : les journalistes ne sont pas des superhéros. Nous n’avons pas été tant surpris que ça par le résultat, sauf peut-être par l’ampleur de la copie. »
Absence de structure
 Le
web
n'est pas
réellement structuré, entendez par là comme, par exemple, la base documentaire du CDI.
Vous
cherchez
un auteur ? Sur e-sidoc, il suffit de chercher dans le champ auteur. Sur le Web,
c'est
moins
évident. La chaîne de caractère cherchée est certes trouvée, mais est-ce bien celle du
nom
d'un
auteur ?
Le
web
n'est pas
réellement structuré, entendez par là comme, par exemple, la base documentaire du CDI.
Vous
cherchez
un auteur ? Sur e-sidoc, il suffit de chercher dans le champ auteur. Sur le Web,
c'est
moins
évident. La chaîne de caractère cherchée est certes trouvée, mais est-ce bien celle du
nom
d'un
auteur ?
A noter ! Sans même parler du Web sémantique [1], il existe de nombreuses tentatives de structuration des données. Par exemple celle de Wikipédia sur les pays ou les sociétés qui permet d'afficher directement un encadré structuré dans les résultats d'un moteur de recherche.
Contenus éphémères
Tout change en permanence sur le Web. Tout se créée et, souvent, disparaît aussi vite, sans toujours de possibilité de le retrouver. Les archives du Web sont quasi vides et il n'y a guère que quelques sites, dont par exemple wayback, pour les stocker.
Problème de fiabilité
Avec l'abondance de sites vient aussi celle du copié-collé, de la retranscription approximative, du pillage d'idée. Il est de plus en plus difficile de valider l'information. Les sites personnels peuvent être de très grande qualité et les sites institutionnels relayer des idées fausses. Savoir chercher devient de plus en plus important.
Une grande concentration médiatique


Une confiance à trouver
Pourquoi 4 Français sur 10 boudent l’information ?
Dans le 33e Baromètre de confiance dans les médias réalisé par Kantar pour « La Croix », l’intérêt des Français pour l’information atteint son plus bas niveau historique. Baromètre médias.
C'est quoi une information ?
C'est quoi une information ?
Discussion au Kebab du quartier. Romain, Leonard, Cindy et Fama se racontent leur week-end. Un seul a une vraie information à donner aux autres : lequel ? Leonard : c’est celui qui raconte quelque chose de vraiment nouveau, qui n’intéresse pas que lui, et qui a des conséquences pour tout le monde. Les clés des médias : c'est quoi une information ?

 www.milan-ecoles.com/
www.milan-ecoles.com/
Qu’est-ce qu’une source ?
Origine de l’information. C’est une notion importante puisqu’elle apporte de précieux éléments de réponse sur la fiabilité d’un article.
Qu’est-ce qu’une source ?
Un projet immobilier est en construction au Sud de Troupaumé. Leonard est au courant de tout ce qu’il y aura : un centre commercial, une salle de sport, un cinéma, etc. Il a une bonne source : son oncle travaille à la mairie et lui raconte plein de choses. Mais il y a autre chose que son oncle lui cache : les commerçants du centre ville qui craignent de perdre leurs clients… Une source c’est indispensable pour avoir des informations, mais elle défend des intérêts. Il faut varier les sources…
Quels outils ?
Chercher c'est tracer
Chaque fois que vous utilisez un moteur de recherche courant, vos données de recherches (votre adresse IP et les cookies de suivi pour enregistrer vos termes de recherche, la date et l'heure de votre visite, et les liens sur lesquels vous avez cliqués…) sont enregistrées.
 La
maîtrise
d'un
moteur de recherche reste évidemment un incontournable, et
ce module pour Google ou celui-ci pour Qwant vous montre de
nombreuses possibilités de
recherche
pas forcément connues de tous.
La
maîtrise
d'un
moteur de recherche reste évidemment un incontournable, et
ce module pour Google ou celui-ci pour Qwant vous montre de
nombreuses possibilités de
recherche
pas forcément connues de tous.
Ces recherches révèlent une quantité immense d'informations personnelles à votre sujet,
comme
vos
intérêts, votre situation de famille, vos penchants politiques, votre état de santé,
etc.
Ces informations constituent aujourd'hui une mine d'or pour les sociétés de
marketing,
les
autorités gouvernementales, les hackers…
Les moteurs de recherche
Ceux qui conservent vos données



Ceux qui ne conservent pas vos données
 Qwant
(www.qwant.com/)qui,
contrairement à
ce que
laisse
suggérer son
nom, est un moteur français.
Qwant
(www.qwant.com/)qui,
contrairement à
ce que
laisse
suggérer son
nom, est un moteur français.
A Lire, la critique très positive faite par le site Korben": « je suis conquis par cette nouvelle version du moteur sortie mi-avril et Google n'est plus, pour moi, un passage obligé sur le net. »
korben.info/
Comment mettre en place la recherche par défaut avec Qwant sur votre navigateur ?
blog.qwant.com/
A noter également, Qwant Junior est plus particulièrement destiné aux enfants. Sans publicité et sans accès aux sites pornographiques et aux sites de E-commerce, il est choisi par l'éducation nationale.
www.qwantjunior.com/?l=fr
 Le
moteur de recherche le plus confidentiel
reste
Ixquick. Pas de
récupération d'adresse IP, les données personnelles ne sont pas transmises à des tiers.
Le
moteur de recherche le plus confidentiel
reste
Ixquick. Pas de
récupération d'adresse IP, les données personnelles ne sont pas transmises à des tiers.
 Dans
le même esprit, citons duckduckgo.com/.
Dans
le même esprit, citons duckduckgo.com/.
Les moteurs spécialisés
 https://archive.org/ permet de
retrouver de vieilles versions de sites ayant changé d'aspect ou des pages disparues
https://archive.org/ permet de
retrouver de vieilles versions de sites ayant changé d'aspect ou des pages disparues
 Copyscape
(www.copyscape.com/)
est un
moteur de recherche de plagiat sur Internet
Copyscape
(www.copyscape.com/)
est un
moteur de recherche de plagiat sur Internet
 Ecosia
(www.ecosia.org/)
reverse 80 %
de ses revenus publicitaires à un programme de plantation d'arbres au Brésil.
Ecosia
(www.ecosia.org/)
reverse 80 %
de ses revenus publicitaires à un programme de plantation d'arbres au Brésil.
![]() Le
moteur
de
recherche de l'éducation permet de limiter les recherches 350 sites publics de
référence de
l'éducation nationale.
Le
moteur
de
recherche de l'éducation permet de limiter les recherches 350 sites publics de
référence de
l'éducation nationale.
 millionshort.com/index.html retire
automatiquement les premiers 100, 1000, 10.000, 100.000 ou 1 million de résultats.
millionshort.com/index.html retire
automatiquement les premiers 100, 1000, 10.000, 100.000 ou 1 million de résultats.
 www.pickanews.com/
est un
moteur de recherche plurimédia européen indexant plus de 50 000 sources médias (presse
imprimée,
web, radio et TV). L'abonnement est payant et permet la mise en place d'alertes).
www.pickanews.com/
est un
moteur de recherche plurimédia européen indexant plus de 50 000 sources médias (presse
imprimée,
web, radio et TV). L'abonnement est payant et permet la mise en place d'alertes).
 Wolfram
est un
moteur de recherche et un langage pour les objets connectés et de réponses aux questions
(posées en
anglais).
Wolfram
est un
moteur de recherche et un langage pour les objets connectés et de réponses aux questions
(posées en
anglais).
Les métamoteurs
Le métamoteur envoie ses requêtes à plusieurs moteurs de recherche et retourne les résultats de chacun d’eux. Pratique. Beaucoup d’entre eux ont disparu ces dernières années. Par exemple Copernic Agent est un logiciel que l'on installait et qui permettait de faire une recherche sur plus de 1000 moteurs. Les résultats étaient ensuite triés (élimination des résultats identiques, filtres de recherche, résumés…). Mais le Google est devenu tellement hégémonique qu'il n'existe plus qu'une version locale.
Citons>
Dogpile tire actuellement ses résultats de Google, Yahoo, Bing, et quelques autres.
www.dogpile.com/
Le canard de Duck Duck Go protège votre identité numérique. a noter, un système très efficace de raccourcis clavier les “bangs” qui permettent de lancer directement une recherche sur des services comme Amazon, YouTube et autres Twitter.
duckduckgo.com/
SearX récupère les résultats de recherche à partir de nombreuses sources qui incluent des sources célèbres comme Google, Yahoo, DuckDuckGo, Wikipedia, etc. SearX est open source
searx.me
Les annuaires
Au tout début du WEB, les sites étaient classés dans des annuaires, ce qui permettait par
exemple de
parcourir une arborescence.
Par exemple : Formation -> Enseignement supérieur ->Universités : France
->
Université
de la Réunion pour trouver 15 réponses en quelques clics.
2 principaux modes d'accès permettent de consulter les ressources sélectionnées :
- Arborescence des thèmes
- Thèmes de A à Z
Les encyclopédies et dictionnaires en ligne
Rendus célèbres par l'encyclopédie en ligne Wikipédia, les Wikis, ces outils collaboratifs ont peu à peu gagné le Web.
Du Web aux wikis : une histoire des outils collaboratifs
interstices.info/
Evidemment la première ressource est le plus souvent Wikipédia. Ni diabolique, ni indispensable quoi que quelquefois incontournable, l'essentiel est de savoir l'utiliser à bon escient.
Le principe du Programme de formation à Wikipédia est simple : les éducateurs et les étudiants du monde entier sont invités à contribuer sur Wikipédia et sur les autres projets Wikimédia dans un environnement pédagogique.
Guide Wikipédia pour contribuer
upload.wikimedia.org/
Il existe d'autres dictionnaires et encyclopédies en ligne, par exemple :
Pour aller plus loin !
 L'urfist de Rennes propose une liste de 80
outils de recherche spécialisés : entres autres recherche de sons, de fichiers,
de
diapositives, de personnes, d'archives…
L'urfist de Rennes propose une liste de 80
outils de recherche spécialisés : entres autres recherche de sons, de fichiers,
de
diapositives, de personnes, d'archives…
Le logiciel documentaire
Qu'est-ce qu'un logiciel documentaire ?
Un SGBD
(Système
de
Gestion de Bases de Données) est un logiciel qui prend en charge la structuration, le
stockage, la
mise à jour et la maintenance d'une base de données. Dans le cas particulier des CDI, le
logiciel de
gestion et de recherche documentaire, permet, comme son nom l'indique de créer, gérer,
chercher des
notices documentaires. De nouvelles fonctionnalités sont aussi souvent proposées
(gestion de
panier,
recherche dans d'autres bases de données, envoi de données…).
Il est de plus en plus souvent en ligne.
Si ces logiciels permettent également des recherches d'information, le plus souvent sur des bases de sites sélectionnés, leur principale fonction est de trouver des documents disponibles au CDI.
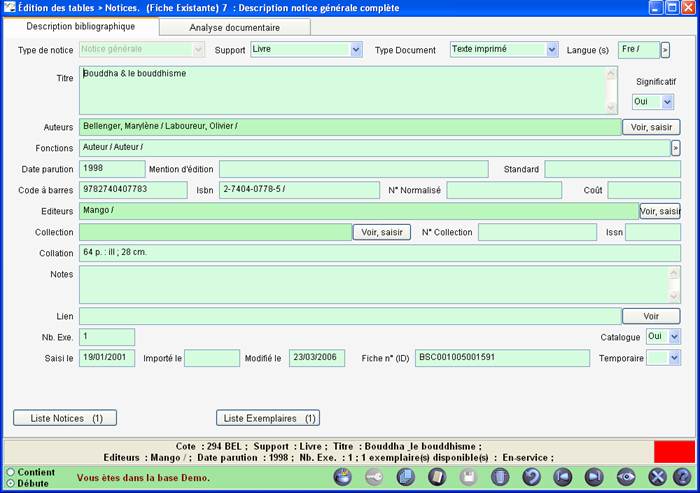
Tous les documents présents au CDI font l'objet de la création d'une notice documentaire, dans laquelle différents champs sont renseignés, notamment le titre, l'auteur, l'éditeur etc. ainsi qu'un résumé indicatif et des mots clés sélectionnés dans un thésaurus.
Un thésaurus est une liste fermée (environ 15 000 entrées reliées entre-elles par une hiérarchie) de mots clés.
L'utilisation d'un thesaurus pour attribuer des descripteurs (mots clés) permet notamment :
- de limiter la multiplicité des formes (XiX, XIX, 19 siècle, 19ème siècle 19° siècle etc.)
- de chercher y compris sur des mots non indexés (par exemple un document indexé avec le descripteur " planète " va permettre de faire une recherche sur les termes spécifiques de "planète" à savoir " Jupiter ", " Mars " etc.).
Par exemple la recherche suivante
https://9740001h.esidoc.fr/recherche/plan?support_groupe=Livres
va faire une recherche avec le mot clé exoplanète mais afficher aussi les fiches
contenant le mot planète.
Autrement dit, le thésaurus va augmenter les capacités de réponses du système de gestion.
Un livre de recettes culinaires par exemple, ne fera jamais l'objet d'une notice par recettes, ce serait beaucoup trop long à réaliser, mais sera indexé avec le descripteur " recettes culinaires ". Et c'est en consultant le document, que l'on pourra vérifier qu'il contient bien la recette recherchée.
Logiciel documentaire et/ou moteur de recherche ?
Une recherche de type documentaire est donc très différente de celle par exemple mise en œuvre sur Internet. Il y a peu de chance pour qu'il y ait justement LE document qui traite de VOTRE question.
Un fonds de CDI bien doté va comprendre environ 20 000 documents soient 100 000 notices.
Votre recherche va se faire sur 100 000 notices, à partir du titre, de l'auteur, de mots clés, du résumé, du thésaurus…
Autrement dit, si votre (vos) mot(s) clé(s) est contenu dans l'une des notices (ou via une recherche élargie automatiquement dans le thesaurus) la fiche résultat sera affichée.
C'est exactement la même chose avec un moteur de recherche. Si le mot clé est présent quelque part dans la page Web, y compris sous forme de métadonnées la page est affichée.
La manière de faire une recherche sera forcément différente selon l'outil utilisé.
Les mots clés utilisés avec un logiciel documentaire seront moins nombreux, plus généraux, et saisis au singulier.
Ceux utilisés avec un moteur devront être précis, le plus précis possible, nombreux en gardant toujours à l'esprit qu'ils devront se trouver dans la page résultante.
Le logiciel documentaire du CDI est souvent la solution documentaire e-sidoc. En connaissez-vous toutes les possibilités de recherche, d'exploitation de l'information ?
L'ordre de présentation
C'est un algorithme secret qui détermine l'ordre de présentation des réponses en fonction de votre profil. Autrement dit, la même requête faite par deux personnes ne retournera pas forcément les mêmes réponses dans le même ordre.
Les critères de géolocalisation, la langue, les recherches précédentes et beaucoup d'autres critères seront ici déterminants.
Une recherche avec le mot clé "météo" va afficher celle de votre région.
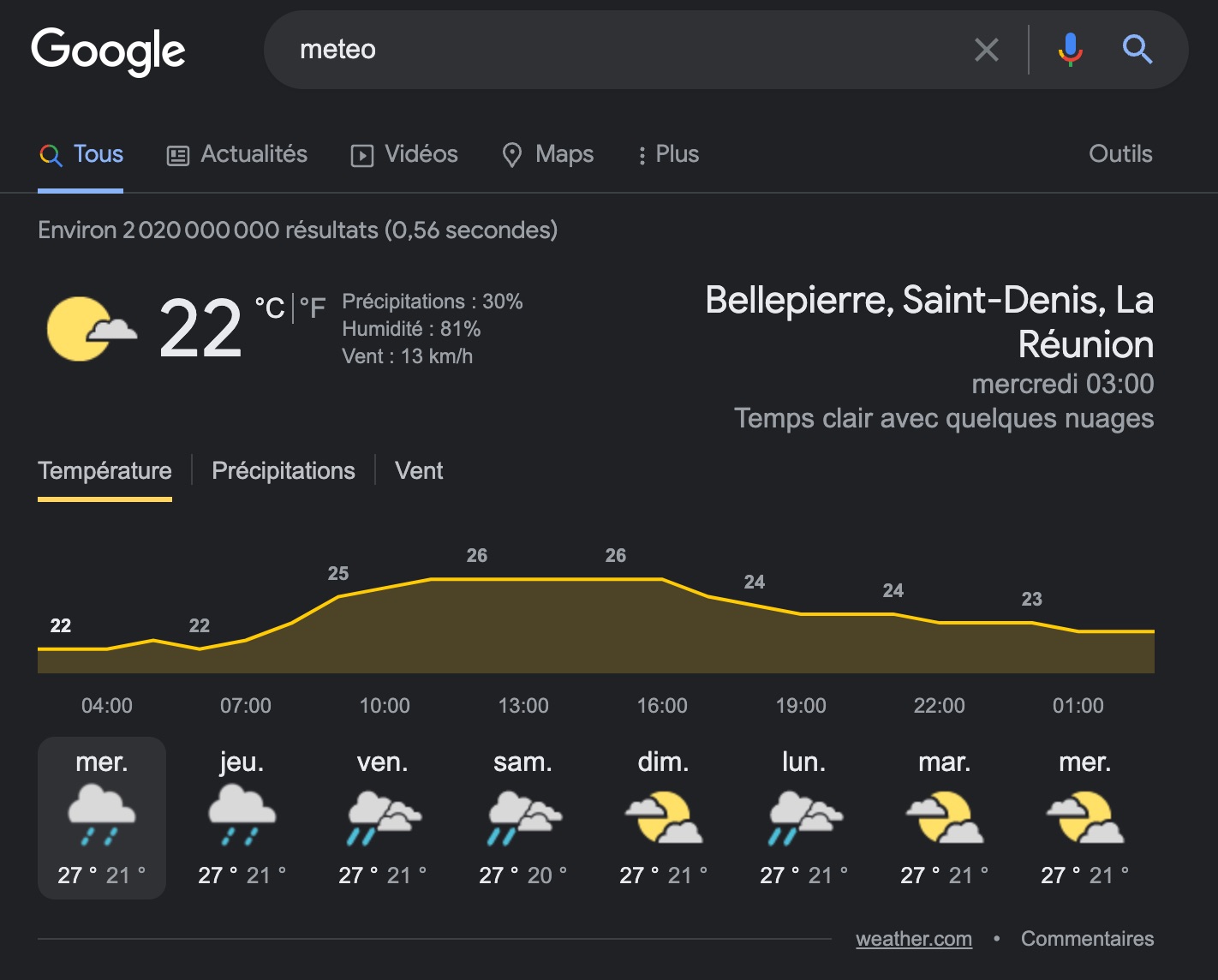
La manière de présenter
La manière de présenter les réponses ne provient pas non plus du hasard. Des publicités sont souvent judicieusement placées et contextualisées.
 Le
darknet
Le
darknet
{kind=link}